Using sentiment analysis for clickbait detection in RSS feeds
post, Oct 19, 2019, on Mitja Felicijan's blog
Initial thoughts
One of the things that interested me for a while now is if major well
established news sites use click bait titles to drive additional traffic to
their sites and generate additional impressions.
Goal is to see how article titles and actual content of article differ from each
other and see if titles are clickbaited.
Preparing and cleaning data
For this example I opted to just use RSS feed from a new website and decided to
go with The Guardian World news. While this gets
us limited data (~40) articles and also description (actual content) is trimmed
this really doesn't reflect the actual article contents.
To get better content I could use web scraping and use RSS as link list and
fetch contents directly from website, but for this simple example this will
suffice.
There are couple of requirements we need to install before we continue:
pip3 install feedparser (parses RSS feed from url)pip3 install vaderSentiment (does sentiment polarity analysis)pip3 install matplotlib (plots chart of results)
So first we need to fetch RSS data and sanitize HTML content from description.
import re
import feedparser
feed_url = "https://www.theguardian.com/world/rss"
feed = feedparser.parse(feed_url)
# sanitize html
for item in feed.entries:
item.description = re.sub('<[^<]+?>', '', item.description)
Since we now have cleaned up data in our feed.entries object we can start with
performing sentiment analysis.
There are many sentiment analysis libraries available that range from rule-based
sentiment analysis up to machine learning supported analysis. To keep things
simple I decided to use rule-based analysis library
vaderSentiment from
C.J. Hutto. Really nice library and quite easy to
use.
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
analyser = SentimentIntensityAnalyzer()
sentiment_results = []
for item in feed.entries:
sentiment_title = analyser.polarity_scores(item.title)
sentiment_description = analyser.polarity_scores(item.description)
sentiment_results.append([sentiment_title['compound'], sentiment_description['compound']])
Now that we have this data in a shape that is compatible with matplotlib we can
plot results to see the difference between title and description sentiment of an
article.
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (15, 3)
plt.plot(sentiment_results, drawstyle='steps')
plt.title('Sentiment analysis relationship between title and description (Guardian World News)')
plt.legend(['title', 'description'])
plt.show()
Results and assets
- Because of the small sample size further conclusions are impossible to make.
- Rule-based approach may not be the best way of doing this. By using deep
learning we would be able to get better insights.
- Next step would be to periodically fetch RSS items and store them over a
longer period of time and then perform analysis again and use either machine
learning or deep learning on top of it.
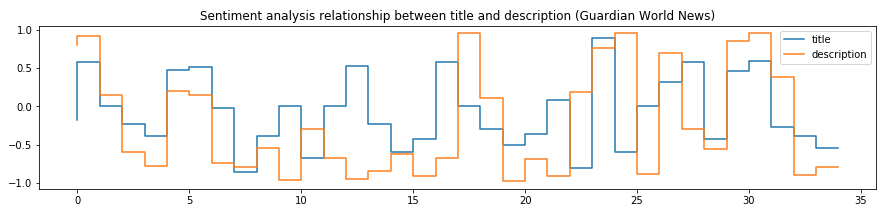
Figure above displays difference between title and description sentiment for
specific RSS feed item. 1 means positive and -1 means negative sentiment.
» Download Jupyter Notebook
Going further